
Deploy Firecrawl | Open-Source Web Scraper - Apify, Scrapy Alternative
Self-host Firecrawl on Railway. Scrape/Crawl website to .md, LLM extraction
DBs
NUQ-Postgres
Just deployed

Redis
Just deployed
/data
Firecrawl Playwright
Just deployed
Firecrawl API
Just deployed
RabbitMQ
Just deployed

Deploy and Host Firecrawl on Railway
Self-host Firecrawl on Railway — the open-source web scraping API that turns any website into clean, AI-ready markdown. Firecrawl handles JavaScript rendering, crawling, structured extraction, and site mapping so your AI pipelines always get usable data, not raw HTML soup.
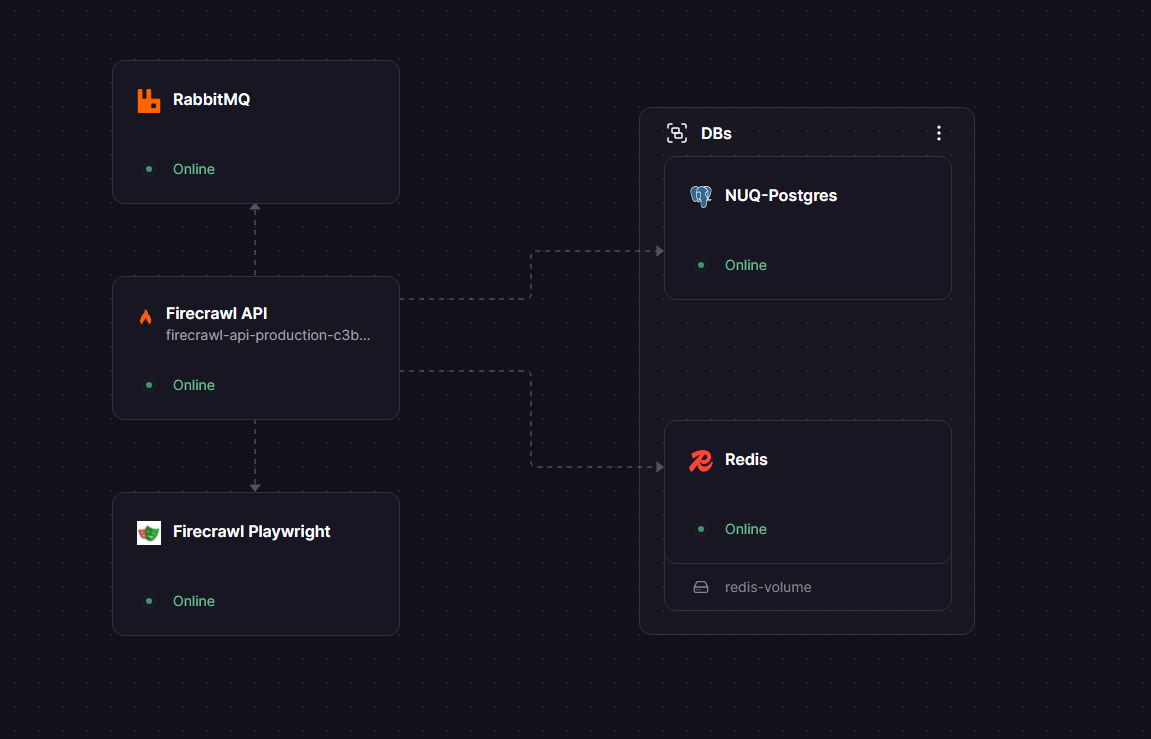
This template deploys the full Firecrawl stack from scratch: firecrawl-api (the REST API), firecrawl-playwright (headless Chromium for JS rendering), nuq-postgres (the NUQ job-queue database), Redis (caching and rate-limiting), and RabbitMQ (async job brokering) — all pre-wired with internal Railway networking.
Getting Started with Firecrawl on Railway
Once deployed, your API is immediately available at the Railway public domain shown on the firecrawl-api service. No signup or API key is required by default (USE_DB_AUTHENTICATION=false). All requests are plain JSON over HTTPS.
> Note: The /v1/scrape extract format and any LLM-powered extraction require a valid OPENAI_API_KEY set on the firecrawl-api service. Set it in Railway → Firecrawl API → Variables before using those features.
1. Health check — confirm the API is live:
curl https://.up.railway.app/
# → {"message":"Firecrawl API","documentation_url":"https://docs.firecrawl.dev"}
2. How to scrape a single URL using Firecrawl? (returns clean markdown):
curl -X POST https://.up.railway.app/v1/scrape \
-H "Content-Type: application/json" \
-d '{"url": "https://example.com", "formats": ["markdown"]}'
3. How to crawl an entire site using Firecrawl? (async job — returns a crawl ID):
# Start crawl
curl -X POST https://.up.railway.app/v1/crawl \
-H "Content-Type: application/json" \
-d '{"url": "https://example.com", "limit": 20, "scrapeOptions": {"formats": ["markdown"]}}'
# Poll for results using the returned crawl ID
curl https://.up.railway.app/v1/crawl/
4. How to map a site using Firecrawl? (get all URLs without scraping content):
curl -X POST https://.up.railway.app/v1/map \
-H "Content-Type: application/json" \
-d '{"url": "https://example.com"}'
5. How to do LLM-powered structured extraction using Firecrawl? — requires OPENAI_API_KEY:
curl -X POST https://.up.railway.app/v1/scrape \
-H "Content-Type: application/json" \
-d '{
"url": "https://news.ycombinator.com",
"formats": ["extract"],
"extract": {
"prompt": "Extract the top 5 stories with title, URL, points, and comment count."
}
}'
About Hosting Firecrawl on Railway
Firecrawl is an open-source (AGPL-3.0) web-to-markdown API built by Mendable AI. It solves one of the hardest problems in AI engineering — reliably getting clean, structured content from the web — by combining a headless browser, async job queuing, and LLM-friendly output formats.
Key capabilities:
- Scrape — converts any URL to markdown, HTML, screenshots, or raw text
- Crawl — discovers and processes all pages of a website automatically
- Map — returns all URLs on a site without downloading page content
- Extract — uses an LLM to pull structured JSON from pages via a natural-language prompt
- JS rendering — Playwright-powered Chromium handles SPAs and dynamic pages
- PDF support — parses web-hosted PDFs and document files
This is a multi-service deployment: firecrawl-api orchestrates jobs, firecrawl-playwright handles browser rendering, nuq-postgres stores the job queue, Redis handles caching and rate limiting, and RabbitMQ brokers async crawl messages between workers.
Why Deploy Firecrawl on Railway
One-command deployment, no infrastructure management needed:
- Zero cold-start config — all 5 services are pre-wired with internal Railway networking
- Private by default — playwright, Redis, RabbitMQ, and nuq-postgres are internal-only
- Auto-scaling ready — Railway handles container restarts and resource scaling
- Persistent Redis — Railway Redis plugin includes a managed volume
- Isolated queue DB —
nuq-postgresuses the custom Firecrawl image with pg_cron pre-installed
Common Use Cases
- RAG pipelines — feed LangChain, LlamaIndex, or CrewAI with clean markdown from live websites
- AI training data — bulk-crawl documentation sites, blogs, or product pages for fine-tuning datasets
- Competitive intelligence — monitor competitor pricing pages, release notes, or job boards automatically
- Lead enrichment — extract structured contact and company data from prospect websites
Firecrawl vs Apify vs ScrapingBee
| Feature | Firecrawl (self-hosted) | Apify | ScrapingBee |
|---|---|---|---|
| Open-source | ✅ AGPL-3.0 | ❌ | ❌ |
| Native markdown output | ✅ | ❌ HTML/JSON | ❌ HTML |
| LangChain / LlamaIndex | ✅ built-in | ❌ custom | ❌ custom |
| JS rendering | ✅ all tiers | ✅ | 💰 $249+ tier only |
| Pricing model | infra cost only | compute units | per-credit |
| MCP server | ✅ | ❌ | ❌ |
Firecrawl's markdown output reduces LLM token usage by ~67% compared to passing raw HTML. For teams building AI applications that ingest web content, this directly cuts inference costs.
Dependencies for Firecrawl
firecrawl-api—ghcr.io/firecrawl/firecrawl:latest— REST API, job orchestration, LLM extractionfirecrawl-playwright—ghcr.io/firecrawl/playwright-service:latest— headless Chromium, port 3000 (internal)nuq-postgres—ghcr.io/firecrawl/nuq-postgres:latest— NUQ job queue with pg_cron schema (internal)Redis— Railway Redis plugin — rate limiting and caching (internal)rabbitmq—rabbitmq:3-alpine— async crawl job brokering (internal)
Environment Variables Reference
| Variable | Service | Required | Description |
|---|---|---|---|
OPENAI_API_KEY | firecrawl-api | For extract only | LLM-powered structured extraction. Not needed for scrape/crawl/map. |
USE_DB_AUTHENTICATION | firecrawl-api | No | Set true to require API keys (needs Supabase). Default: false (open access). |
NUM_WORKERS_PER_QUEUE | firecrawl-api | No | Parallel scrape workers. Default: 8. Increase for higher throughput. |
Deployment Dependencies
- GitHub: github.com/mendableai/firecrawl
- Docs: docs.firecrawl.dev
- Self-hosting guide: docs.firecrawl.dev/contributing/self-host
Hardware Requirements for Self-Hosting Firecrawl
| CPU | RAM | Storage | |
|---|---|---|---|
| Minimum | 2 cores | 4 GB | 5 GB |
| Recommended | 4+ cores | 8 GB | 20 GB |
| Runtime | Node.js 22 | — | Postgres volume for nuq-postgres |
Playwright (headless Chromium) is the most memory-intensive component. Under sustained crawl load, 4 GB is insufficient — plan for 8 GB+ in production.
Self-Hosting Firecrawl
Docker Compose (from the official repo):
git clone https://github.com/mendableai/firecrawl.git
cd firecrawl
cp apps/api/.env.example apps/api/.env
# Edit .env — set OPENAI_API_KEY if needed
docker compose up
Minimal env config for self-hosting:
# apps/api/.env
PORT=3002
REDIS_URL=redis://redis:6379
PLAYWRIGHT_MICROSERVICE_URL=http://playwright-service:3000/scrape
USE_DB_AUTHENTICATION=false
NUM_WORKERS_PER_QUEUE=8
# Optional — only needed for /v1/scrape with "extract" format:
OPENAI_API_KEY=sk-...
The Railway template handles all of this automatically — services are pre-connected using internal Railway private domains.
Is Firecrawl Free? Pricing
Firecrawl is open-source (AGPL-3.0) — self-hosting is free. The cloud version at firecrawl.dev offers a free tier (500 credits/month), a Hobby plan at $16/month (3,000 credits), and a Standard plan for higher volumes.
When self-hosted on Railway, you pay only for Railway infrastructure — typically a few dollars per month at light usage, scaling with compute and egress.
FAQ
What is Firecrawl? Firecrawl is an open-source web scraping API that converts websites into clean markdown, structured JSON, or screenshots. It handles JavaScript-rendered pages, crawls entire sites, and supports LLM-powered data extraction.
Do I need an OpenAI API key to self host Firecrawl?
Only for the extract format in /v1/scrape — which uses an LLM to pull structured data from pages. Scraping, crawling, mapping, and screenshot features work without any OpenAI key.
Why is nuq-postgres a separate service instead of Railway's standard Postgres?
Firecrawl's job queue system (NUQ) requires a custom Postgres image with the pg_cron extension and a pre-loaded nuq schema. A standard Postgres instance doesn't have this schema, so the API workers can't find their queue tables.
Why is Playwright running as a separate service? Firecrawl delegates all browser-based rendering to a dedicated microservice. This keeps the API process lightweight and lets you scale the browser tier independently from the API workers.
Can I enable API key authentication?
Yes — set USE_DB_AUTHENTICATION=true on firecrawl-api, then add a Supabase instance and configure SUPABASE_URL, SUPABASE_ANON_TOKEN, and SUPABASE_SERVICE_TOKEN. Without Supabase, the auth system won't initialize.
Does Firecrawl work with LangChain or LlamaIndex?
Yes. Both have native Firecrawl integrations — FirecrawlLoader for LangChain and FirecrawlReader for LlamaIndex. Point them at your Railway URL instead of the cloud API.
Template Content
Firecrawl Playwright
ghcr.io/firecrawl/playwright-service:latestFirecrawl API
ghcr.io/firecrawl/firecrawl:latestNUQ-Postgres
ghcr.io/firecrawl/nuq-postgres:latestRabbitMQ
rabbitmq:3-alpineRedis
redis:8.2.1