
Deploy Hermes Agent | OpenClaw Alternative on Railway [Jun'26]
[Jun'26] Hermes AI agent – faster & smarter than OpenClaw & Claude agents.
hermes-agent
Just deployed
/opt/data
Deploy and Host Hermes AI Agent on Railway
Hermes is an open-source AI agent framework with persistent memory, multi-step tool use, and full LLM-agnostic design — connect OpenAI, Anthropic, Groq, Ollama, or any OpenAI-compatible endpoint without changing a line of agent logic. Unlike AutoGPT or CrewAI which require complex local setup, Hermes deploys as a production-ready agent service on Railway in under 5 minutes with PostgreSQL-backed memory and Redis session handling pre-configured out of the box.
What This Template Deploys
| Service | Purpose |
|---|---|
| Hermes Agent | Core AI agent runtime — LLM routing, tool execution, session management, and API serving on port 3000 |
| PostgreSQL | Persistent memory storage — conversation history, session state, and agent context survive restarts and redeploys |
| Redis | Session cache layer — concurrent conversation handling and high-throughput request management |
All services connect over Railway's private network. Credentials are injected automatically via reference variables — no manual connection string configuration required.
About Hosting Hermes
Running a production AI agent requires a persistent runtime with database-backed memory, secure credential management for LLM API keys, and a public HTTPS endpoint for integrations and webhooks. Without a managed host, you're configuring Docker, inter-service networking, SSL, and environment variable handling manually.
Railway provisions all of it automatically. Hermes runs as an always-on agent service — persistent memory, secret management, and HTTPS are handled out of the box.
Typical cost: ~$5–10/month on Railway's Hobby plan for the full three-service stack. Compare that to OpenAI Assistants API which charges $0.10 per 1,000 tool calls plus session time on top of token costs — at any meaningful usage volume, self-hosting pays for itself within the first month.
Deploy in Under 5 Minutes
- Click Deploy on Railway and wait for the build to complete (~3–5 minutes)
- Set
LLM_API_KEYandLLM_PROVIDERin the Variables tab - Railway auto-detects
DATABASE_URLandREDIS_URL— Hermes initializes persistent memory on first boot automatically - Open your Railway-assigned URL — Hermes is live and ready to handle requests
No SSH. No Docker configuration. No reverse proxy setup.
Common Use Cases
-
Self-hosted alternative to AutoGPT — run a persistent, memory-backed AI agent on your own Railway infrastructure without AutoGPT's complex local Python setup or Docker dependency management
-
Self-hosted alternative to OpenAI Assistants API — bring your own LLM provider, pay flat Railway compute instead of per-tool-call API fees, and keep conversation history in your own PostgreSQL instance
-
Multi-channel AI agent via Telegram and WhatsApp — connect Hermes to Telegram bots or WhatsApp via Evolution API; the agent maintains per-user conversation memory across sessions
-
AI agent with persistent memory across sessions — unlike stateless LLM API calls, Hermes stores full conversation context in PostgreSQL; users continue where they left off after hours or days without re-explaining their context
-
LLM-agnostic agent infrastructure — swap between OpenAI, Anthropic Claude, Groq, or local Ollama models without rewriting agent logic; useful for cost optimization or provider fallback
-
Private AI assistant with zero data leakage — all conversations, tool outputs, and memory stay on your Railway PostgreSQL instance; no data sent to third-party analytics or SaaS
Configuration
| Variable | Required | Description |
|---|---|---|
LLM_API_KEY | ✅ Required | API key for your chosen LLM provider |
LLM_PROVIDER | ✅ Required | Provider — e.g. openai, anthropic, groq |
AGENT_NAME | Optional | Agent display name across sessions — defaults to Hermes |
DATABASE_URL | ✅ Auto-injected | PostgreSQL connection string via Railway reference variable |
REDIS_URL | ✅ Auto-injected | Redis URI via Railway reference variable |
LLM_BASE_URL | Optional | OpenAI-compatible endpoint — Ollama, vLLM, or OpenRouter |
PORT | Pre-set | 3000 — auto-configured by Railway |
NODE_ENV | Pre-set | production |
Hermes vs. Alternatives
| Hermes (self-hosted) | AutoGPT | CrewAI | LangGraph | |
|---|---|---|---|---|
| Persistent memory | ✅ PostgreSQL + Redis | ⚠️ File-based | ❌ Session only | ⚠️ Manual setup |
| One-click cloud deploy | ✅ Railway | ❌ Local only | ❌ Local only | ❌ Local only |
| LLM agnostic | ✅ Any provider | ✅ Yes | ✅ Yes | ✅ Yes |
| Self-hosted and private | ✅ Yes | ✅ Yes | ✅ Yes | ✅ Yes |
| Production HTTPS | ✅ Auto via Railway | ❌ Manual | ❌ Manual | ❌ Manual |
| Multi-step tool chaining | ✅ Yes | ✅ Yes | ✅ Yes | ✅ Yes |
| Setup complexity | ✅ Low — browser config | ❌ High — local Docker | ❌ Medium — Python env | ❌ High — custom code |
Dependencies for Hermes Hosting
- API key from at least one LLM provider (Anthropic Claude or OpenAI recommended)
- Railway account — Hobby plan (~$5–10/month) covers all three services
- Optional: Ollama or vLLM endpoint for zero API cost local model inference
Deployment Dependencies
- Hermes GitHub Repository — source code and configuration reference
- Railway Documentation — platform guides for scaling and secrets
- OpenAI API Documentation — LLM backend integration
- Railway Volumes Documentation — optional persistent storage
Implementation Details
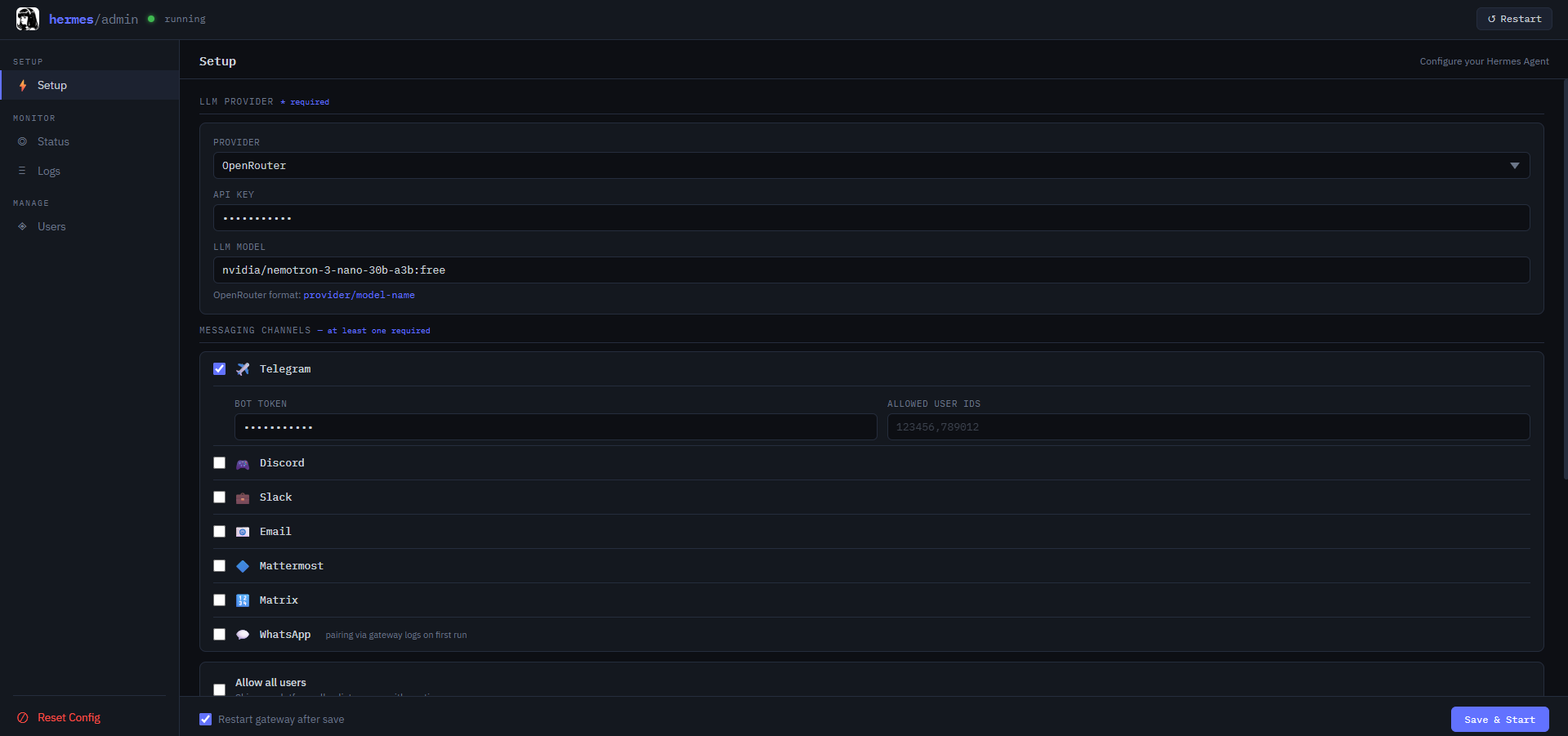
This template deploys the Hermes agent runtime alongside Railway-managed PostgreSQL and Redis
over private internal networking. Database and cache ports are never exposed publicly. On first
boot, Hermes auto-detects DATABASE_URL and REDIS_URL and initializes its memory schema.
All session state and conversation history persist across restarts without re-initialization.
The agent API is served at your Railway public HTTPS domain on port 3000.
Frequently Asked Questions
How much does Hermes cost compared to AutoGPT Cloud or OpenAI Assistants? Hermes on Railway runs at ~$5–10/month flat for the full three-service stack. OpenAI Assistants API charges per tool call and per session second on top of token costs — at moderate usage, that compounds quickly. AutoGPT Cloud pricing is usage-based with no self-hosted option. Hermes gives you unlimited agent sessions at predictable flat compute pricing.
What makes Hermes different from AutoGPT or CrewAI? AutoGPT and CrewAI are primarily local frameworks — they run on your machine and require Python environment management, Docker setup, and manual configuration to expose publicly. Hermes is designed for cloud deployment: persistent PostgreSQL memory, Redis session handling, and HTTPS are pre-configured. You get a production agent service, not a local script.
Does Hermes retain memory between conversations? Yes. Session state and conversation history are stored in PostgreSQL. Hermes retrieves prior context on every new conversation from a returning user — no re-introduction needed, no context lost between sessions, restarts, or redeploys.
Can I switch LLM providers without changing agent logic?
Yes. Update LLM_PROVIDER and LLM_API_KEY in Railway Variables and redeploy. Agent logic,
tool definitions, and memory are fully decoupled from the provider layer.
Can I run Hermes with a local model instead of a cloud API?
Yes. Set LLM_BASE_URL to any OpenAI-compatible endpoint — Ollama, vLLM, or LM Studio. This
enables fully private deployments where no conversation data leaves your Railway environment.
Is my data private? Yes. Hermes is self-hosted on Railway. Conversations, tool outputs, and agent memory stay in your PostgreSQL instance. API keys are stored as encrypted Railway environment variables and are never logged or sent to third-party services.
Why Deploy Hermes on Railway?
Railway is a singular platform to deploy your infrastructure stack. Railway will host your infrastructure so you don't have to deal with configuration, while allowing you to vertically and horizontally scale it.
By deploying Hermes on Railway, you get a production-ready AI agent with persistent memory, LLM-provider flexibility, automatic HTTPS, and zero server administration — at flat Railway compute pricing instead of per-call API fees.
Template Content
hermes-agent
Shinyduo/hermes-agent